
[ad_1]
With 2.93 billion monthly active users, Facebook has become an essential platform for businesses to reach and engage with their target audience.1 However, manually collecting data from Facebook can be time-consuming and resource-intensive. Manual web scraping is prone to errors and inaccuracies, especially for large-scale data collection processes.
Fortunately, Facebook scraping tools, also known as Facebook scrapers, allow businesses and individuals to collect data more efficiently and accurately.
In this article, we explain how to scrape Facebook while respecting Facebook’s terms of service and users’ privacy and review some of the top Facebook scrapers available today. We also discuss best practices for using Facebook scrapers, including legal and ethical considerations.
What is Facebook scraping?
Facebook scraping refers to extracting data from Facebook that is accessible to the public. While it is possible to scrape Facebook manually, it typically refers to automated processes carried out with a web crawler.
Is it legal to scrape Facebook?
It is legal to scrape publicly available data in compliance with Facebook’s terms of service. Facebook has strict policies against web scraping, and collecting data from the platform without its permission is considered unethical and illegal.2
What measures does Facebook take to prevent unauthorized scraping?
- External data misuse (EDM) team: The External Data Misuse (EDM) team at Facebook is responsible for detecting potential data misuse and preventing unauthorized scrapers from violating Facebook’s policies and user privacy.
- Rate limits: Refers to the number of times a user can interact with a website’s services in a given time period. Facebook applies rate limits to prevent the overuse and abuse of its APIs. Rate limits are typically imposed on data collection activities to manage incoming connection requests and ensure the performance of a server.
- Request blocking through pattern recognition: Facebook employs pattern recognition algorithms to identify and block requests that resemble malicious or abusive patterns. This technique involves analyzing the traffic and requests received by the server by using machine learning algorithms.
For example, suppose a user makes connection requests repeatedly to the same web server without rotating their IP address. In that case, the target server will identify the user’s behavior as suspicious and take action to prevent abuse or unauthorized access.
Facebook scraping: best practices for ethical and legal data collection
Here are some best practices for collecting data from Facebook ethically and complying with Facebook policies:
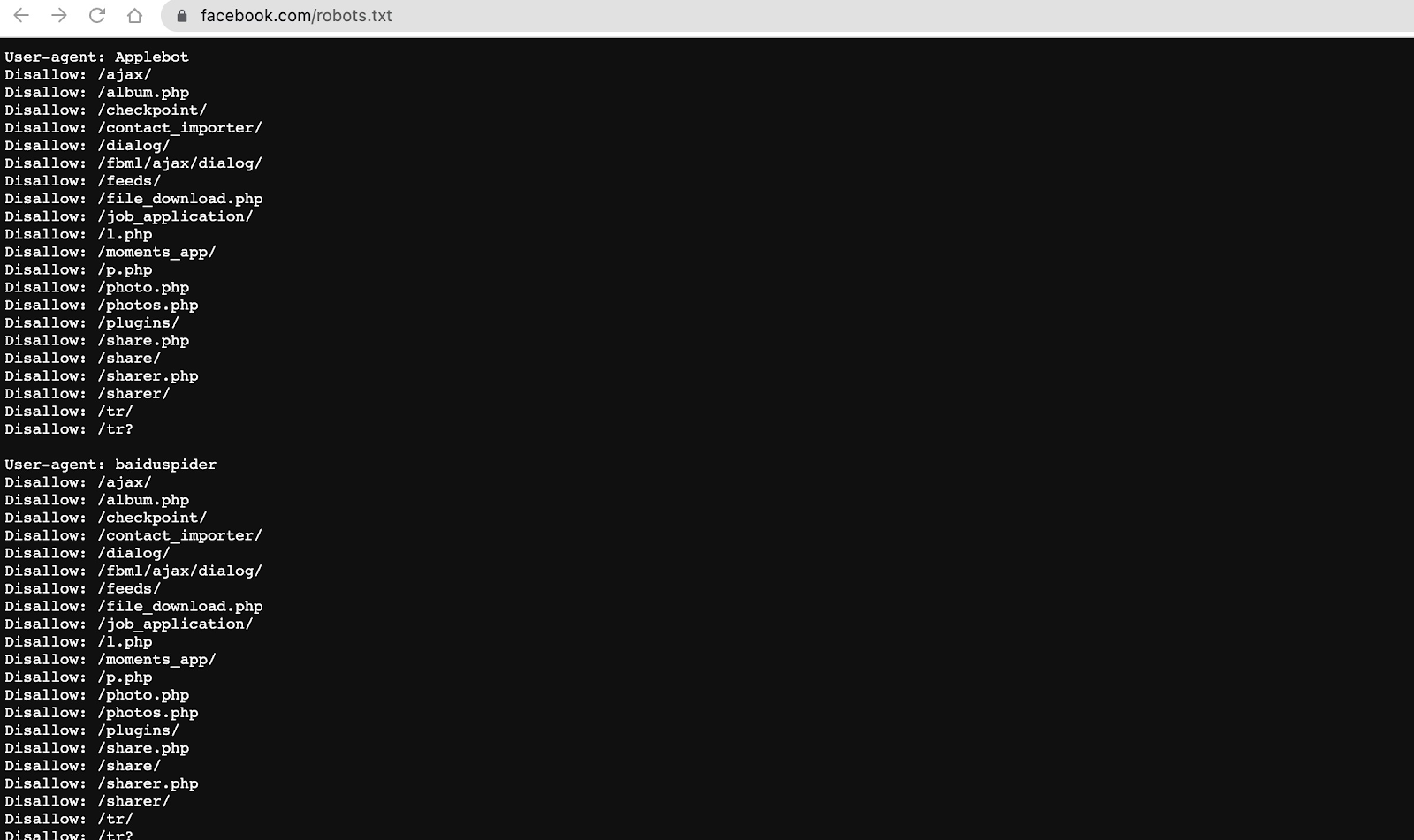
- Check Facebook’s robots.txt file: Before collecting data, it is important to check the robots.txt file of the website you want to scrape. The robots.txt file contains a set of rules that tell web crawlers and other automated agents which parts of the website they can access and which parts they cannot access (Figure 1).
If the robots.txt file indicates that certain web pages should not be crawled or indexed, it is crucial to adhere to these instructions and avoid crawling those pages.
Figure 1: Facebook’s robots.txt file
- Use Facebook APIs: Facebook provides Platform APIs that enable developers to access and extract various data types on Facebook. 4 It is important to respect users’ privacy and follow Facebook’s policies and terms of service while collecting data.
- Monitor API usage: You must monitor your API usage to avoid exceeding Facebook’s rate limits. This may result in temporary or permanent API access blocks. You can use a monitoring tool, track usage metrics, such as API calls, and set up alerts to ensure make sure you are not violating any rate limits.
- Adhere to Facebook’s policies: To ensure that your web scraping activities are ethical and legal, it is essential to abide by the policies of websites while collecting data.
- Provide transparency: You must be transparent about the purpose of your web scraping by providing clear and concise information on how user data is collected and used.
- Protect user privacy: Do not collect personally identifiable information (PII); mask any personally identifiable information from the data you collect to protect user privacy.
What Facebook Data Can You Scrape?
Social media web scraping can infringe on user privacy and lead to data abuse. If you want to collect data from a social media network, you must scrape publicly available data and comply with applicable laws and regulations such as the General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA). Here are some examples of data that can be scraped from Facebook:
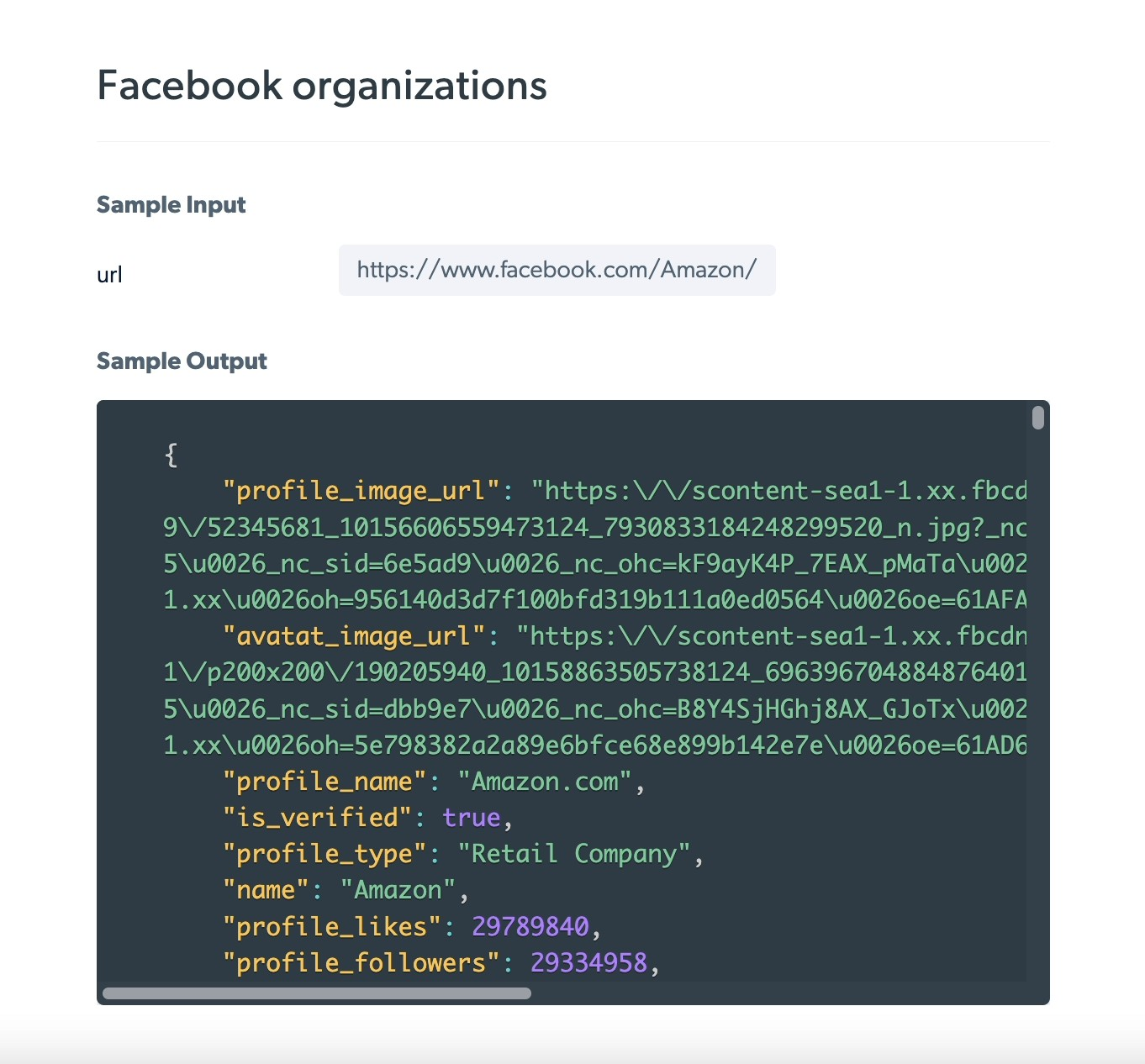
- Pages: Facebook pages, including page descriptions, contact information, and followers (Figure 2).
Figure 2: The output of a scraped Facebook organization page
- Ads: Facebook ads, including the number of impressions, ad IDs, and targeting criteria.
- Events: Including event name, location, and attendees.
- Profiles: Username, profile URL, location, likes and other personal details.
- Hashtags: Post URL and media URL.
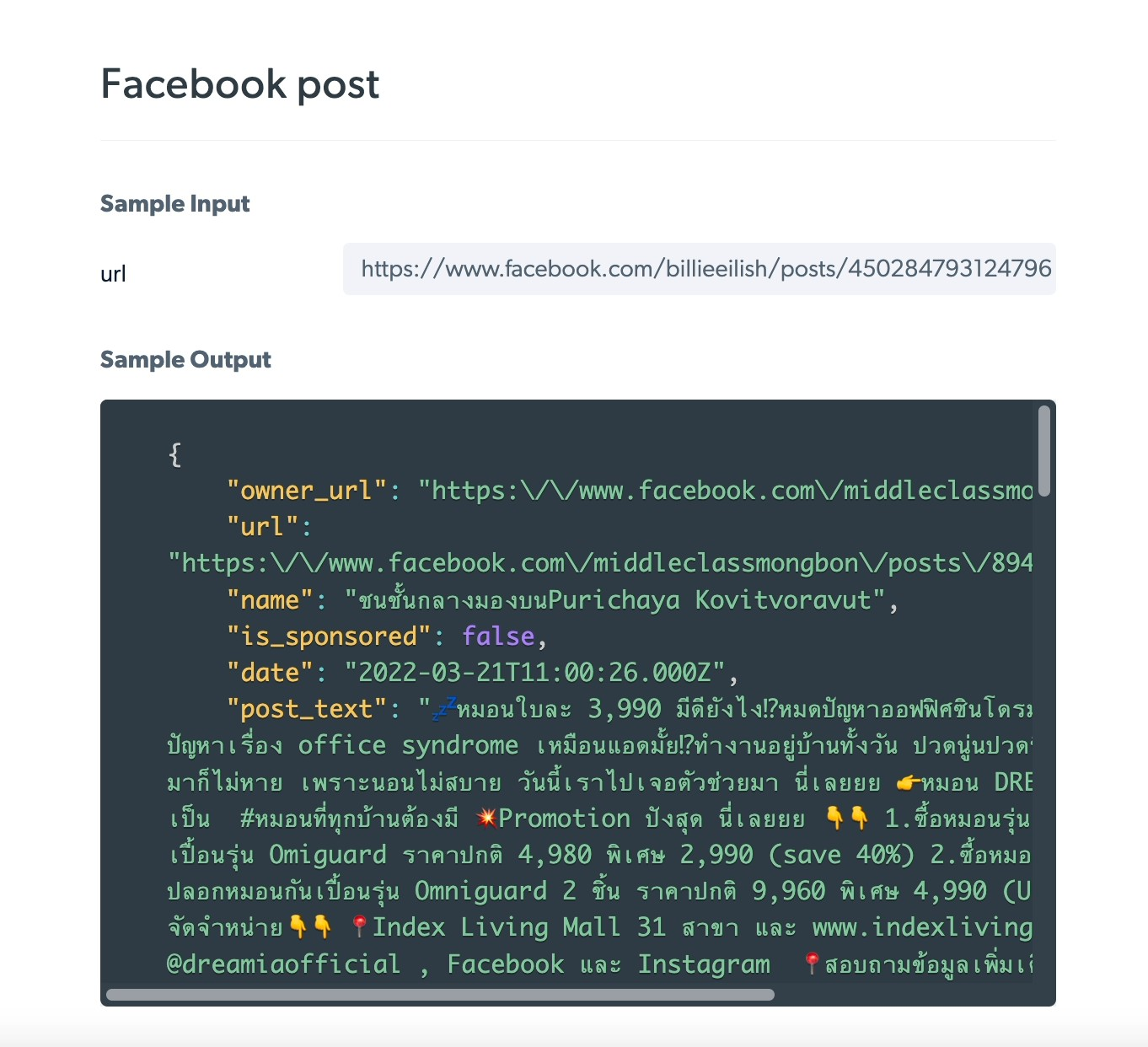
- Posts: User’s posts, including text, images, and videos (Figure 3).
Figure 3: Sample output of a scraped Facebook post
Facebook APIs for data collection
Facebook APIs allow developers to access various data types on Facebook, including user profiles, photos, and posts. 5 Here is an overview of how to use Facebook APIs for data collection:
- Register your application: You must first register your application with Facebook to gain access to data through the APIs.
- Choose the API endpoint: Once the application is registered, you must choose an API endpoint corresponding to the information you intend to collect.
- Make connection requests: You can make API requests, typically HTTP requests, to Facebook to extract data.
- Track API usage: Facebook limits the number of API requests that can be made per application to prevent misuse and overuse of APIs. You need to monitor your API usage to avoid rate limiting.
Facebook APIs provide authorized and controlled access to data since they are provided by the website itself. Using APIs for data collection enables users to ensure compliance with data protection laws and regulations by providing controlled access to the desired data.
Facebook Scrapers for data collection
We compiled a list of the top 5 Facebook scrapers for collecting data from Facebook, such as posts, comments, and user profiles. It is important to note that each Facebook scraper’s specific features and limitations may vary depending on the pricing plan.
Although many of these Facebook scrapers provide free plans, some of their advanced features may require a paid subscription. It’s important to carefully examine each tool’s pricing plan to determine which features are included with the free plan and which require a paid subscription.
| Features | Pricing | Free Trial | |
|---|---|---|---|
| Bright Data | ▸ Browser scripting in JavaScript ▸ Auto-scaling infrastructure ▸ Unlocking technology ▸ Built-in debug tools ▸ Data parsing |
▸ $500/mo – Custom ▸ Pay as you go |
✅ |
| Smartproxy | ▸ Cloud data storage ▸ Free Chrome extension ▸ Unlocking technology ▸ Automatic proxy rotation |
▸ $50/mo | ✅ |
| ScrapingBot | ▸ JS Rendering (Headless Chrome) ▸ Proxy support ▸ Geotargeting |
▸ Free Plan ▸ €39/mo – €699/mo |
❌ |
| Apify | ▸ Datacenter and residential proxies ▸ Support Python and JavaScript libraries ▸ IP rotation |
▸ Free Plan ▸ $49/ mo -$499 /mo |
❌ |
| Octoparse | ▸ IP Rotation and CAPCTHA solving ▸ Built-in tools ▸ Cloud Service |
▸ Free Plan ▸ $89/mo – $249/mo |
✅ |
Facebook Datasets
Web scraping can be a technically complex and time-consuming process, as it typically requiring knowledge of programming languages and data processing skills. If you lack programming skills or do not have a technical team, you can prefer using pre-made datasets rather than web scraping. Pre-made datasets are an ethical and efficient way to gather Facebook data. They can save time and resources by providing access to a large volume of already formatted and cleaned data.
Sponsored
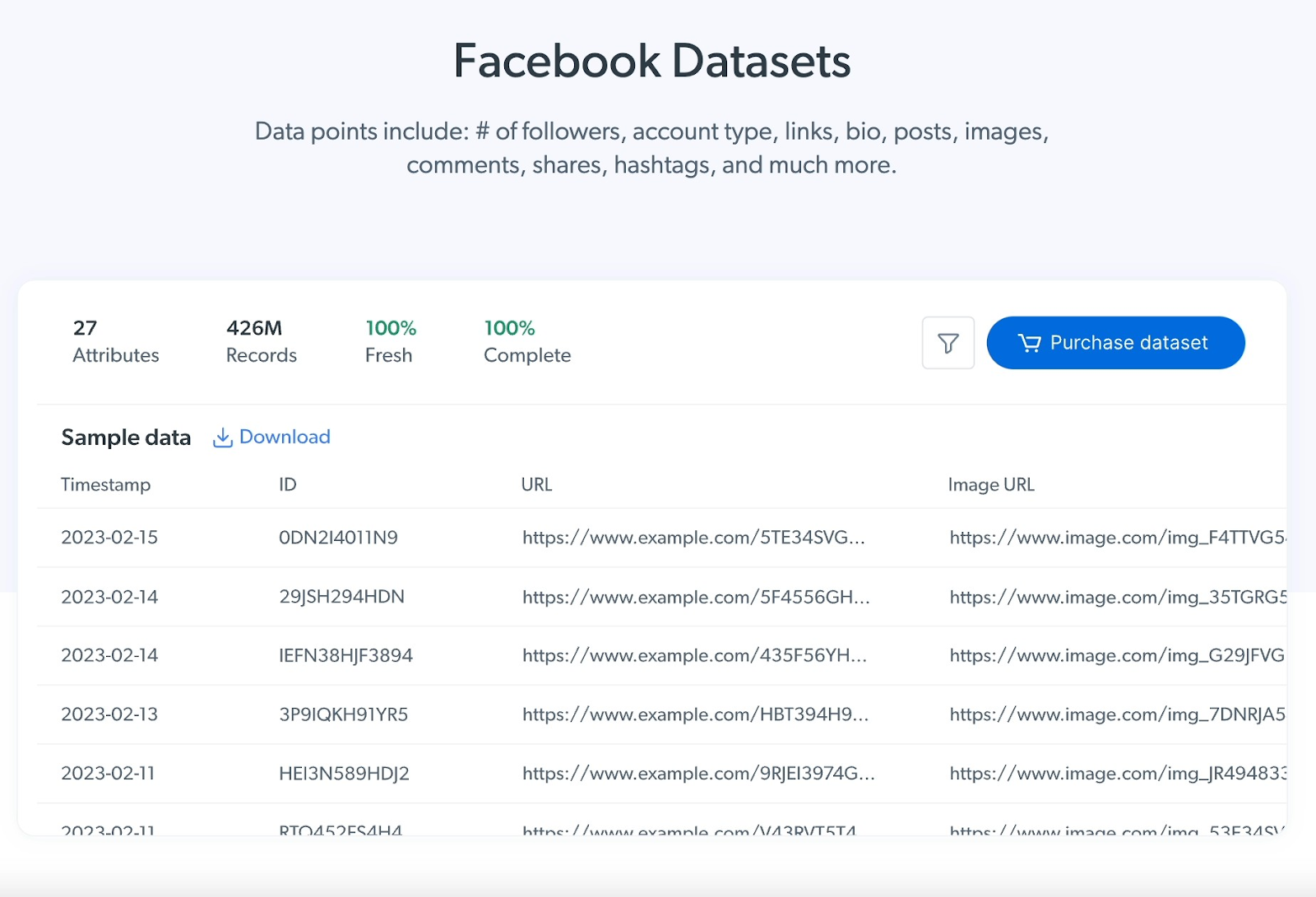
Bright Data Facebook Datasets include different data points, including # of followers, links, bio, posts, images, comments and hashtags (Figure 4). You can customize output fields to your specific web scraping requirements.
Figure 4: A sample of Bright Data’s Facebook Datasets
Python-based scrapers for Facebook scraping
Python offers a wide range of open-source libraries and frameworks for web scraping, such as Scrapy, Beautiful Soup and Selenium. Here’s an example of how to scrape a website using Python language:
- Install the required libraries: Install the necessary library to your Python environment based on the requirements of your specific project. You can use pip to install a library.
- Import the required libraries: Once the installation is complete, you can import the library using the import statement in your Python code.
- Make a request: You must send a request to the target website to retrieve the desired information.
- Parse the HTML content: Once you’ve obtained the HTML content, you’ll need to parse it to extract useful information. Beautiful Soup, for example, includes a built-in HTML parser in Python and other third-party Python parsers, such as HTML5lib and lxml.
- Locate the desired data: Python libraries enable developers to locate the desired data on a web page. For instance, MechanicalSoup supports XPaths and CSS Selectors, which allow users to find document elements. After locating the required data, you can extract it.
- Save the extracted data: You can save the data collected to a file or database.
Check out the list of popular Python libraries to determine which ones correspond with your data collection projects.
Alternative data sources to Facebook for collecting data
1. Instagram
90% of users follow a business account on Instagram. 6 By scraping Instagram data, businesses can gain valuable insights into their target audience, competitors, and industry trends. There are many scraping tools available, including Instagram scrapers and web scraping APIs to extract data from Instagram.
Instagram provides different API endpoints for businesses and developers to access and get data. For example, Instagram Graph API extract metadata and metrics about other Instagram business and creator accounts (Figure 5). However, Instagram uses rate limits to prevent each app and app user from overusing APIs.
Figure 5: An example of making a request using API

2. TikTok
TikTok is a popular social media platform for businesses seeking to connect with a younger audience and achieve other market goals, such as influencer marketing and advertising. For instance, most of TikTok’s user base comprises Generation Z, which can help businesses build brand awareness and connect with younger millennials.
However, manually scraping large amounts of data is challenging. For data collection, you can utilize a no-code TikTok scraper or Python libraries such as TikTokApi and TikTokPY.
Figure 6: Sample output of a scraped TikTok profile using URL input

3. Twitter
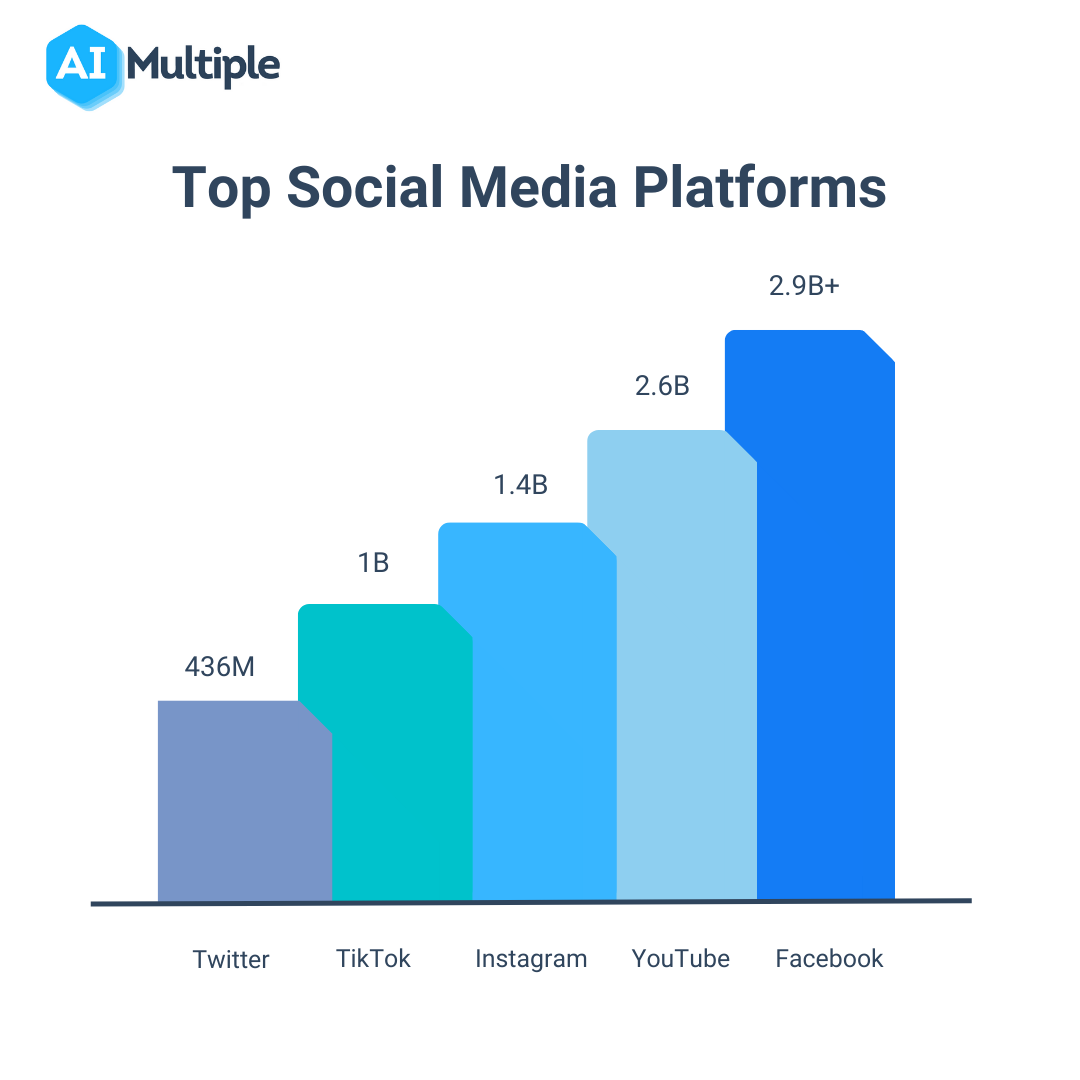
Twitter is one of the most popular social media platforms worldwide, with 436 million monthly active users in 2022 (Figure 7). Twitter data can be a valuable resource for businesses for brand monitoring, trend analysis, and public opinion analysis. Several methods for obtaining publicly available Twitter data, including no-code Twitter scrapers, Twitter APIs, and Python scraping libraries.
Twitter provides API access to developers, allowing them to retrieve Twitter data, such as tweets and user profiles. Twitter API is compatible with various programming languages, including Python and Ruby. To use Twitter’s API, you must first register your application on the Twitter Developer website.
Figure 7: Top social media platforms worldwide in 2022
Transparency statement:
AIMultiple works with many companies, including Bright Data mentioned in this article.
Download our whitepaper on web scraping if you want to learn more about it:
Get Web Scraping Whitepaper
Check out our data-driven list of web scrapers for help choosing the right tool, and get in touch with us:
Find the Right Vendors
- Newberry, C. (January 17, 2023) “42 Facebook Statistics Marketers Need to Know in 2023“.Hootsuite.
- Facebook-Automated Data Collection Terms
- Facebook-Automated Data Collection
- Facebook APIs
- Instagram Businesses
- Facebook – Mate for Developers
- Lyons, K. (Nov 01, 2022). “28 Top Social Media Platforms Worldwide”
Semrush

Gülbahar is an AIMultiple industry analyst focused on web data collections and applications of web data.

[ad_2]
Source link

