
[ad_1]
The most important LightGBM parameters, what they do, and how to tune them

LightGBM is a popular gradient-boosting framework. Usually, you will begin specifying the following core parameters:
objectiveandmetricfor your problem settingseedfor reproducibilityverbosefor debuggingnum_iterations,learning_rate, andearly_stopping_roundfor training
But where do you go from here? LightGBM has over 100 parameters [2] that can be tuned. Additionally, each parameter has one or more aliases, which makes it difficult for beginners to get a clear picture of the essential parameters.
Thus, this article discusses the most important and commonly used LightGBM hyperparameters, which are listed below:
In the following, the default values are taken from the documentation [2], and the recommended ranges for hyperparameter tuning are referenced from the article [5] and the books [1] and [4].
In contrast to XGBoost, LightGBM grows the decision trees leaf-wise instead of level-wise. You can use num_leaves and max_depth to control the size of a single tree.

The parameter num_leaves controls the maximum number of leaves in one tree [2].
- Default: 31
- Good starting point for baseline: 16
- Tuning range: (8, 256) with
num_leaves < 2^(max_depth)[3]
The parameter max_depth controls the maximum depth for the tree model [2].
- Default: -1 (no limit)
- Good starting point for baseline: Default
- Tuning range: (3, 16)
The smaller the trees (small num_leaves and max_depth), the faster the training speed — but this can also decrease accuracy [3].
Since num_leaves impacts the tree growth in LGBM more than max_depth [5], Morohashi [4] doesn’t necessarily recommend tuning this parameter and to deviate from the default value.
Aside from the depth and number of leaves, you can specify under which conditions a leaf will split. Thus, you can specify how the tree will grow.

min_data_in_leaf and min_gain_to_split (Image by the author)The parameter min_data_in_leaf specifies the minimum number of data points in one leaf [2]. If this parameter is too small, the model will overfit to the training data [2].
- Default: 20
- Good starting point for baseline: Default
- Tuning range: (5, 300) but depends on the size of the dataset. Hundreds are enough for a large dataset [3]. As a rule of thumb: The larger the dataset, the larger
min_data_in_leaf.
The parameter min_gain_to_split specifies the minimum gain a leaf has to have to perform a split [2].
- Default: 0
- Good starting point for baseline: Default
- Tuning range: (0, 15)
If you limit tree growth by increasing the parameter min_gain_to_split, the resulting smaller trees will lead to a faster training time — but this can also decrease accuracy [3].
Data sampling is a technique to force the model to generalize. The general idea is not to feed the model all the data at each iteration. Instead, the model will only see a fraction of the training data at each iteration.
Bagging
At every bagging_freq-th iteration, LGBM will randomly select bagging_fraction * 100 % of the data to use for the next bagging_freq iterations [2]. E.g., if bagging_fraction = 0.8 and bagging_freq = 2, LGBM will sample 80 % of the training data every second iteration before training each tree.
This technique can be used to speed up training [2].
- Default:
bagging_fraction = 1.0andbagging_freq = 0(disabled) - Good starting point for baseline:
bagging_fraction = 0.9andbagging_freq = 1 - Tuning range:
bagging_fraction(0.5, 1)

Sub-feature sampling
At every iteration, LGBM will randomly select feature_fraction * 100 % of the data [2]. E.g., if feature_fraction = 0.8, LGBM will sample 80 % of the features before training each tree.
- Default: 1
- Good starting point for baseline: 0.9
- Tuning range: (0.5, 1)

While sub-feature sampling can also be used to speed up training like bagging [2], it can help if there is multicollinearity present in the features [1].
You can apply regularization techniques to your Machine Learning model to deal with overfitting. As the parameter names already suggest, the parameter lambda_l1 is used for L1 regularization and lambda_l2 for L2 regularization.
- L1 regularization penalizes the absolute values of the weights and thus is robust against outliers
- L2 regularization penalizes the sum of squares of the weights and thus is sensitive to outliers
You can either decide to use only one of the two types of regularization or you can combine them if you like.
For both parameters, the parameter values behave similarly:
- Default: 0 (disabled)
- Good starting point for baseline: Default
- Tuning range: (0.01, 100)
This article gave you a quick rundown of the most essential LightGBM hyperparameters to tune. Below you can find an overview of them with their recommended tuning ranges.
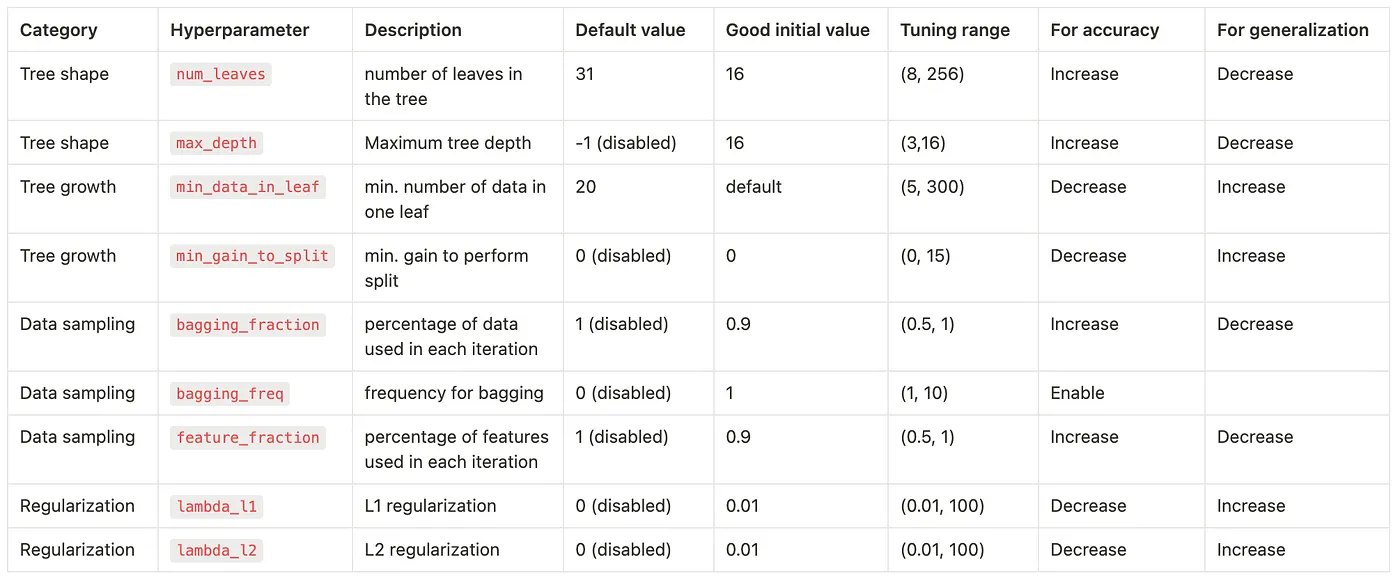
Of course, LightGBM has many more hyperparameters you can use.
For example, the parameter min_sum_hessian_in_leaf specifies the minimal sum hessian in one leaf and can also help with overfitting [2]. There is also a parameter scale_pos_weight you can tune when your dataset is imbalanced. Or you can specify the maximum number of bins a feature will be bucketed into with max_bin.
[1] K. Banachewicz, L. Massaron (2022). The Kaggle Book. Packt
[2] LightGBM (2023). Parameters (accessed March 3rd, 2023)
[3] LightGBM (2023). Parameters Tuning (accessed March 3rd, 2023)
[4] M. Morohashi (2022). Kaggleで磨く機械学習の実践力.
[5] Bex T. (2021). Kaggler’s Guide to LightGBM Hyperparameter Tuning with Optuna in 2021 (accessed March 3rd, 2023)
Source link
