
[ad_1]

Figure 1. Interest in data observability.1
In today’s data-driven world, data observability has emerged as a critical strategy for ensuring data reliability. With data becoming more important for decision-making and analysis, data quality and accuracy are more important than ever. The practice of measuring and monitoring data systems to ensure their dependability, integrity, and accuracy is known as data observability.
According to Google Search Results, interest in data observability has grown since the middle of 2021 (Figure 1). As a result, interest in data observability is new, and many business leaders are unaware of it. Data observability can enable business leaders to make better-informed decisions based on accurate, reliable, and high-quality data, resulting in improved business outcomes and a competitive advantage. Hence, to provide business leaders with a competitive advantage, we explain data observability in this article, including its:
- Importance
- Use cases
- Benefits
- Best practices
What is data observability?

Figure 2. Data observability components.2
Data observability is the practice of continuously measuring, monitoring, and analyzing data systems to ensure data systems’:
- Reliability
- Integrity
- Accuracy
Data observability encompasses the ability to:
Data observability can be considered as an essential aspect of modern data management because it can:
- Provide a comprehensive view of the data ecosystem
- Enable organizations to proactively address data quality issues.
5 Pillars of Data Observability

Figure 3. 5 Pillars of data observability. 3
Data observability can be crucial for maintaining reliable and high-quality data systems; the five key pillars that can contribute to achieving this goal are:
- Distribution: Distribution is analyzing data patterns and distributions to identify anomalies and maintain data quality.
- Freshness: Freshness is ensuring that data is regularly updated and accessible to provide timely insights and maintain relevance.
- Schema: Schema is monitoring schema consistency and structure to prevent data integrity issues and maintain a robust data model.
- Lineage: Lineage is tracking data provenance and lineage to enhance traceability and facilitate debugging of data-related issues.
- Volume: Volume is managing data scale and storage to optimize performance and resource usage while handling large amounts of information.
Note that the order of the pillars above can only provide a rough sequence from data collection (distribution) to system performance (volume). The specific importance of the pillars can vary depending on requirements of a particular project or data system.
How data observability can help avoid data quality challenges
3 Data quality challenges
As organizations rely more on data for decision-making, data quality issues can have significant consequences, in the following manner:
- Compromised analyses: Data quality issues can lead to distorted or incomplete data, undermining the validity of data-driven analyses and potentially leading to misleading conclusions.
- Inaccurate insights: Poor data quality can lead to misrepresentation of underlying facts, resulting in insights that do not accurately reflect the true state of the business or market, stifling effective decision-making.
- Wrong business decisions: Flawed data can lead to incorrect assumptions and conclusions, resulting in business decisions that may not be in the best interests of the organization, ultimately affecting overall performance and growth.
How can data observability help? Top 7 data observability benefits

Figure 4. Data observability business benefits.4
Data observability addresses these concerns by providing a comprehensive view of the data ecosystem, allowing organizations to:
1. Assistance in identifying data quality issues and proactive issue resolution
Data observability can allow organizations to proactively identify and resolve data quality issues before they impact downstream processes or analyses. Data observability can help organizations detect anomalies, inconsistencies, and errors in their data systems. This can enable them to take timely corrective actions. This can reduce the likelihood of:
2. Enhanced data reliability
By continuously monitoring data pipelines and systems, data observability can ensure that data remains accurate and up-to-date, which can improve decision-making.
3. Ensure regulatory compliance
Data observability can help organizations meet regulatory requirements by ensuring data accuracy and consistency. Thereby, it can reduce the risk of non-compliance penalties.
4. Increased operational efficiency
By enabling organizations to optimize their data pipelines and address data quality issues, data observability can contribute to increased operational efficiency. This can translate to:
- Reduced costs
- Faster time-to-insights
- More effective resource utilization by data scientists.
5. Enhanced collaboration
A data observability can foster a shared understanding of data quality across data teams too. Data observability can provide a shared understanding of data quality across teams.This can improve collaboration between data producers and consumers. By providing visibility into data assets, organizations can streamline communication and decision-making. This can ensure that all stakeholders are aligned and working towards the same goals.
6. Improved decision-making
By ensuring data reliability and accuracy, data observability can empower organizations decision making. With access to high-quality data sources, organizations can derive more accurate insights that can lead to more effective strategies and business outcomes.
7. Competitive advantage
High-quality data can allow organizations to stay ahead of their competition and seize new opportunities. Organizations that embrace data observability can gain a competitive advantage by:
- Making more informed decisions that drive innovation.
- Responding more effectively to market trends.
Top 5 data observability use cases
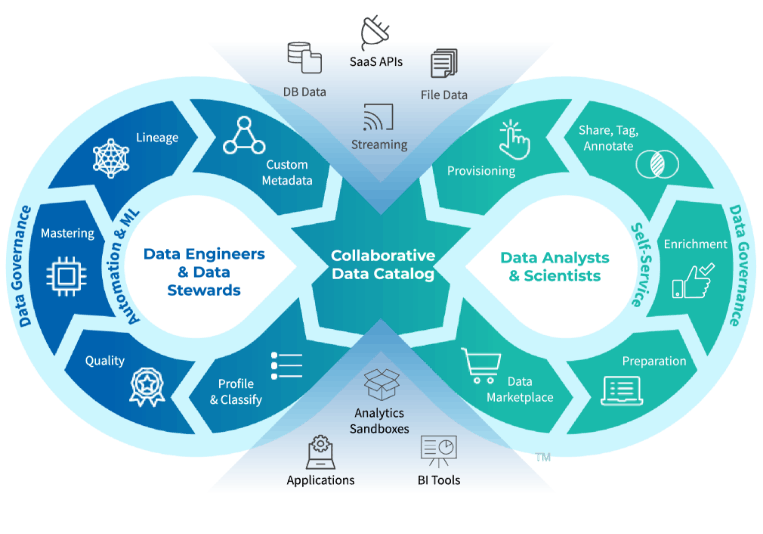
Figure 5. Data Ops diagram.5
Choosing a data observability tool or data platform is determined by your business requirements. As a result, we would like to share with you five common data observability tools use cases.
1. Anomaly detection
Using data observability, organizations can detect:
- Anomalies
- Inconsistencies
- Errors in their data systems.
By continuously monitoring data quality metrics and implementing automated processes, organizations can identify potential issues before they escalate. This can lower the risk of inaccurate analyses and decision-making.
2. Data pipeline optimization
Data operations (DataOps) methodologies, in conjunction with data observability, can assist organizations in identifying:
As a result, data processing can be optimized, operational efficiency can be increased, and data warehouse management becomes more agile.
3. Data governance
Data observability, when combined with DataOps practices, can help data governance initiatives by providing transparency into data lineage and metadata. This can:
- Enable better control over data assets
- Ensure that data policies and standards are consistently followed through automation and collaboration
4. Regulatory compliance
Together, data observability and data operations help organizations meet regulatory requirements by ensuring data:
- Accuracy
- Consistency
- Traceability.
By automating compliance checks and validation processes, the data observability platform can lower the risk of noncompliance penalties.
5. Root cause analysis
Data observability, when combined with DataOps, can enable organizations to conduct root cause analyses and data pipeline monitoring by tracing data issues back to their source. Root cause analysis allows for a better understanding of the underlying factors contributing to data quality issues. This can enable organizations to take corrective actions to prevent future occurrences through continuous improvement and iterative development.
6 data observability best practices
If you consider data observability for your data engineering tools, you should consider the following best practices. To successfully implement data observability, we share six best practices of data observability:
1. Define data quality metrics
Create clear metrics to assess data quality, such as:
These data health metrics should be in line with business goals and data needs.
2. Implement data lineage tracking
Map the data flow from source to destination. This can allow organizations to trace data issues back to their source and understand the impact of changes on downstream systems.
3. Develop a data catalog
Create a centralized repository that documents all data assets, including information related to:
This can enable data engineers to be in a better collaboration and understanding of data across the organization.
4. Monitor data in real-time
Set up real-time data monitoring systems to continuously track data quality metrics and detect anomalies. This can allow organizations to identify and address issues as they arise such as the likelihood of data corruption or loss.
5. Establish data quality thresholds:
Set thresholds for data quality metrics to trigger alerts when data quality falls below acceptable levels. This can help businesses to take immediate action to resolve data downtime issues and maintain data reliability.
6. Foster a data quality culture
Encourage a culture of data quality awareness and responsibility by providing employees:
This can empower individuals to take ownership of data quality and contribute to the organization’s data observability efforts.
If you have further questions on data observability, please contact us at:
Find the Right Vendors
- Google Trends
- “Data Observability – A Crucial Property in a DataOps World”. Eckerson Group. Jul 02, 2018. Retrieved March 15, 2023.
- ”Data Observability”. Cyral. March 15, 2023.
- “WHAT IS OBSERVABILITY AND HOW TO IMPLEMENT IT” APM Experts. March 1, 2020. Retrieved March 15, 2023.
- Teeples, Haley. ‘Data Observability: Data Management Best-Practice Explained’. Zaloni. September 13, 2021. Retrieved March 15, 2023.

Yilmaz Dogukan Ozlu is an industry analyst at AIMultiple. He has a background in philosophy, physics, data analysis, and psycholinguistics.
Prior to working at AIMultiple he took part in a psycholinguistics project where they researched the effect of hand gestures in second language vocabulary acquisition where he discovered his passion for technology.
Dogukan earned his bachelor’s degree in philosophy and physics from Bogazici University. He received his master’s degree in philosophy from the University of Arizona under the funding of the Fulbright Scholarship. Currently, he is a master’s student in Big Data and Business Analytics at Istanbul Technical University.

Source link

