
[ad_1]
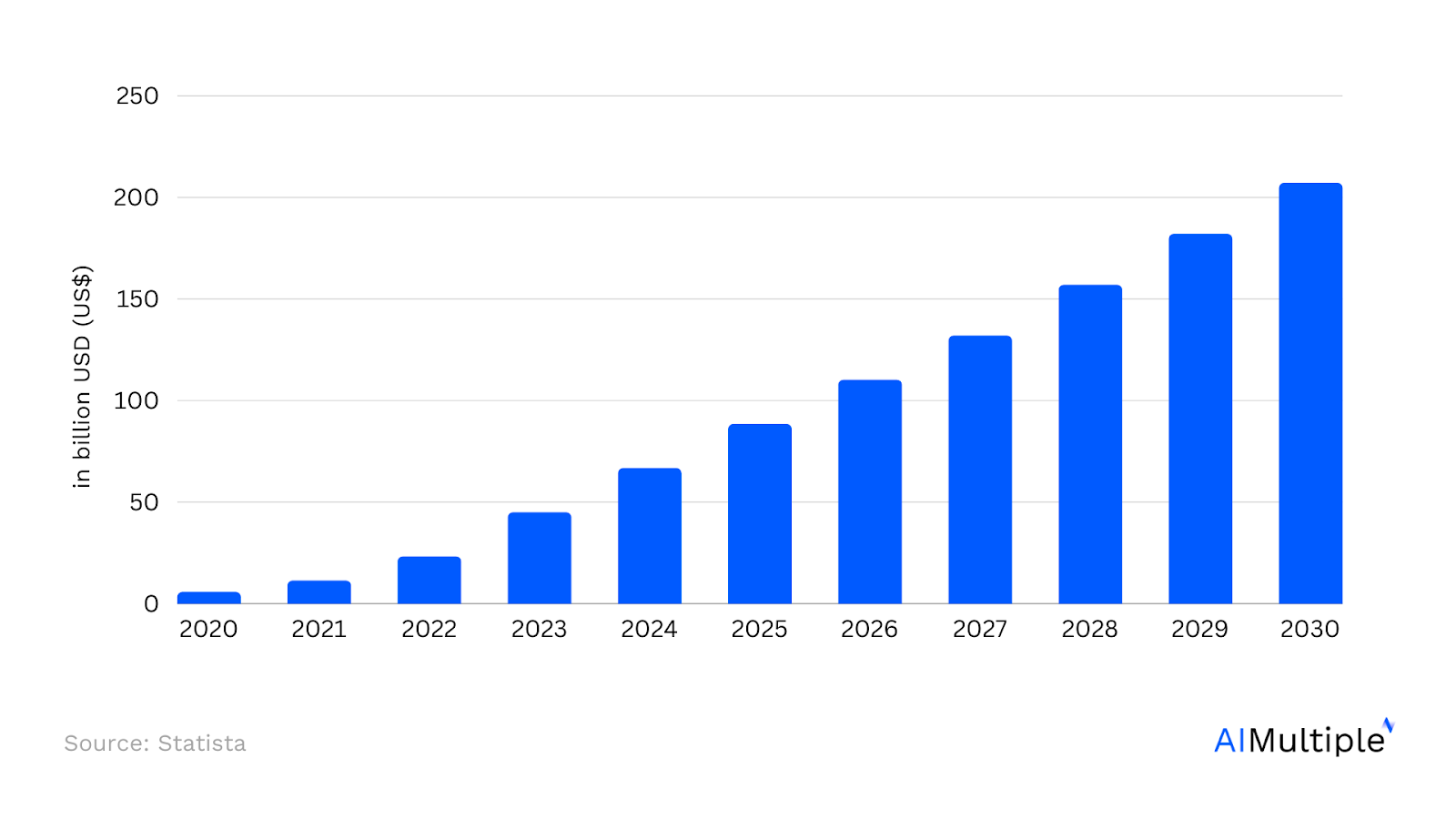
In the rapidly growing market of artificial intelligence (AI) and generative AI (Figure 1), one term that has taken center stage is ‘large language models’, or LLMs. These vast models enable machines to create content like humans. Data plays a foundational role in shaping the behavior, expertise, and range of these models. But how is this data accessed, especially given the emerging challenges?
This article provides a detailed guide on LLM data, helps business leaders decide which method of collection to choose, and provides some options for AI data collection services.
Figure 1. Generative AI market1
What are large language models?
Large Language Models, or LLMs, are a subset of artificial intelligence, falling under the domain of natural language processing (NLP).
These AI models are designed to understand and produce human-like responses in multiple languages, achieving this through massive datasets and deep learning techniques.
Some of the most popular large language models include Generative Pre-trained Transformers (GPT series) and Bidirectional Encoder Representations (BERT).
How are LLMs impacting the tech industry?
LLMs are revolutionizing various sectors:
- Conversational AI: Large language models, are at the heart of many customer service chatbots. They’re designed to understand user inputs and produce human-like interactions, making automated customer support more efficient and user-friendly.
- Language translation: LLMs have revolutionized the way we approach language translation. Whether it’s translating everyday conversations or complex legal documents, these models provide quick and accurate translations, helping to overcome language barriers and foster global communication.
- Programming: Some advanced LLMs have the capability to assist in code generation. This not only makes the coding process more streamlined but also enables business users, who might not have deep technical expertise, to participate in software development.
- Scientific research: LLMs are playing a role in the world of science by assisting researchers. They can translate complex scientific jargon into more understandable terms and provide valuable insights, aiding in data interpretation and accelerating the research process.
Importance of data for LLMs
For a large language model’s performance to be top-notch, it relies heavily on its training data. This data aids in:
- Understanding complex sentences: Context is vital, and having vast amounts of varied data allows LLMs to comprehend intricate structures.
- Sentiment analysis: Gauging customer sentiment or interpreting the tone of text requires a broad range of examples.
- Specific tasks: Whether it’s translating languages or text classification, specialized data helps fine-tune models for dedicated tasks.
However, sourcing this data isn’t always straightforward. With growing concerns about privacy, intellectual property, and ethical considerations, obtaining high-quality, diverse datasets is becoming increasingly challenging.
How do we gather data for LLMs?
This section highlights some popular methods of obtaining relevant data to develop large language models.
1. Crowdsourcing
Data crowdsourcing platform are one of the best sources to gather LLM data. Leveraging a vast global network of individuals to accumulate or label data. This method engages people from diverse backgrounds and geographies to gather unique and varied data points.
Advantages:
- Access to a diverse and expansive range of data points. Since the contributors are located all over the world the dataset is much more diverse.
- Often more cost-effective than traditional data collection methods since there are no additional expenses.
- Accelerates data gathering due to simultaneous contributions from multiple sources.
Challenges:
- Quality assurance can be tricky with varied contributors since you can not physically monitor the work.
- Ethical considerations, especially concerning fair compensation. Many companies like Amazon Mechanical Turk have been penalized for their unfair compensation practices in their crowdsourcing platforms.
Some popular data crowdsourcing services on the market
Here are our top picks:
Clickworker is a crowdsourcing platform offering all sorts of AI data services. Its global network of over 4.5 million workers offers human-generated datasets for different use cases, including LLM development.
Appen is also a popular crowdsourcing platform offering human-generated AI data services. The company’s network consists of over 1 million workers. Check out these articles to learn more about Appen:
2. Automated means
Using automated data collection methods like web scrapers can be used to extract vast amounts of open-source textual data from websites, forums, blogs, and other online sources.
For instance, an organization working on improving an AI-powered news aggregator might deploy web scraping tools to collate articles, headlines, and news snippets from global sources to understand different writing styles and formats.
Advantages:
- Access to a virtually limitless pool of data spanning countless topics.
- Continuous updates due to the ever-evolving nature of the internet.
- Much faster and inexpensive as compared to other modes of collecting language data.
Challenges:
- Ensuring data relevance and filtering out noise can be time-consuming.
- Navigating intellectual property rights and permissions can be challenging and expensive since many online platforms are now charging companies for scraping their data. If developers are scraping without permission, they are facing lawsuits.
Watch this video to see how OpenAI was sued for stealing data from popular authors:
3. Partnership with services
Forming collaborations with academic institutions, research bodies, or corporations to gain proprietary datasets.
For instance, a firm focusing on legal AI tools can collaborate with law schools and legal institutions to access a vast library of legal documents, case studies, and scholarly articles.
Advantages:
- Gaining specialized, meticulously curated datasets.
- Mutual benefits – while the AI firm gains data, the institution might receive advanced AI tools, research assistance, or even financial compensation.
- The data is legal and not subject to lawsuits.
Challenges:
- It can be challenging to establish and uphold trustful partnerships since different organization have different agendas and priorities.
- Balancing data sharing with privacy protocols and ethical considerations can also be challenging since not all organization trust others with their data.
4. Synthetic data
You can also employ AI models or simulations to produce synthetic yet realistic datasets.
For instance, if a virtual shopping assistant chatbot lacks real customer interactions. It can use an AI to simulate potential customer queries, feedback, and transactional conversations.
Advantages:
- Quick generation of vast datasets tailored to specific needs.
- Reduced dependency on real-world data collection, which can be time-consuming or resource-intensive.
Challenges:
- Ensuring the synthetic data closely mirrors real-world scenarios can be challenging since even current powerful AI models sometimes can not provide accurate data.
- Synthetic data cannot work on its own. You will stil require human-generated data to add to the synthetic data.
Here is an article comparing the top synthetic data solutions on the market.
5. Purchasing and licensing
Directly buying datasets or obtaining licenses to use them for training purposes. Online platforms and other forums are now selling their data. For instance, Reddit recently started charging AI developers to access its user-generated-data2.
Advantages:
- Immediate access to large, often well-structured datasets.
- Clarity on usage rights and permissions.
Challenges:
- Can be costly, especially for niche or high-quality datasets.
- Potential limitations on data usage, modification, or sharing based on licensing agreements.
Recommendations
With each method offering its unique advantages and challenges, AI firms and researchers must weigh their needs, resources, and goals to determine the most effective strategies for sourcing LLM data. As the demand for more sophisticated LLMs continues to rise, so too will the innovations in gathering the critical data that powers them.
Further reading
If you need help finding a vendor or have any questions, feel free to contact us:
Find the Right Vendors
External Resources
- Statista Market Insights. (2023). Generative AI – Worldwide. Statista. Accessed: 09/Oct/2023.
- Nicholas, Gordon. (2023). Reddit will charge companies and organizations to access its data—and the CEO is blaming A.I. Fortune. Accessed: 09/Oct/2023
Source link

