
[ad_1]

Methods for scraping web pages include off-the-shelf web scrapers, web scraping APIs, and in-house web scrapers. Each data extraction method would be beneficial depending on your specific data collection requirement. In-house web scrapers are the best option if the website you want to scrape doesn’t support API or you don’t need to outsource the development of web scraping infrastructure.
Cheerio and Puppeteer are two of the most popular Nodejs libraries used by developers to create web crawlers that efficiently extract data from web sources. 1
In this article, we will examine Cheerio and Puppeteer, including their main features, pros, and cons, and outline the key differences between Cheerio and Puppeteer. This way, we aim to help developers choose the most suitable web scraping library for their data collection projects.
Cheerio vs Puppeteer: A detailed comparison
Cheerio and Puppeteer are Node.js libraries that can be used for web scraping and browser automation. There are major differences between these two libraries; the following table outlines the main differences between Cheerio and Puppeteer.
Here’s a quick comparison of Cheerio and Puppeteer ; we will go into more detail about each library in the following sections:
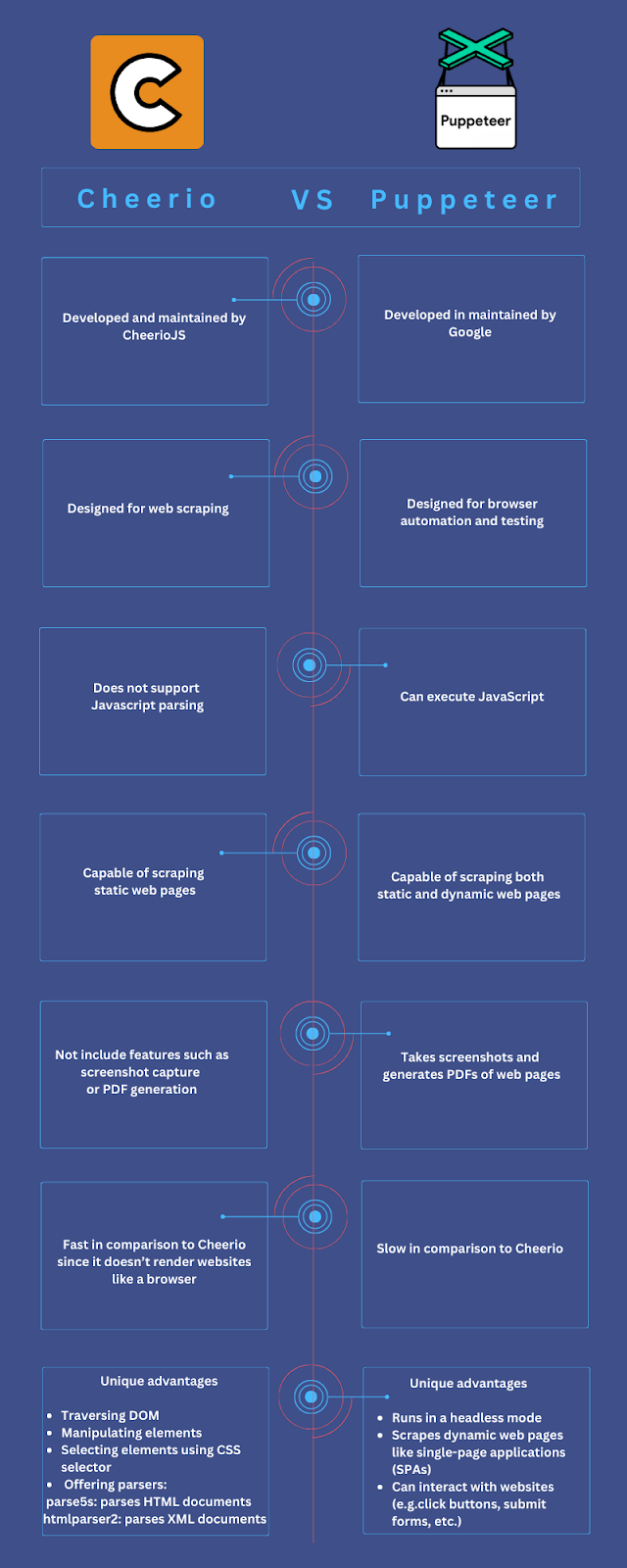
Cheerio evaluation
Cheerio is a Node.js framework for parsing and modifying HTML and XML documents. 2 Cheerio is not a browser automation software such as Selenium, Puppeteer, or Playwright. As a result, it cannot interpret the result the same way that a web browser does. It cannot produce a visual rendering, use CSS, load external resources, or execute JavaScript, which makes Cheerio faster.
Traversing DOM is the act of selecting one element from a neighboring component of a document. Traversing a copy enables you to select and manipulate elements within the document easily. You can traverse in three directions DOM tree using Cheerio:
- Downwards
- Sideways
- Upwards
Cheerio enables developers to manipulate elements within a document based on their specific requirements. You can modify element attributes, add and remove classes, and modify an element’s text content.
You can load HTML documents and parse them into a DOM structure using various methods, such as “load”, “loadBuffer”, “stringStream”, “fromUrl”, etc.,
Figure 3: An example of a CSS selector to select elements from a document

Cheerio enables users to select HTML document elements using CSS selectors. You can select elements based on their tag name, attribute values, etc. Cheerio provides two different parsers based on the source and code of data.
- For parsing HTML documents: parse5
- For parsing XML documents: htmlparser2
Cheerio installation: You must have Node.js installed on your device to install Cheerio. Available operating systems include macOS, Linux, and Windows. You can install Node.js via the package manager as well 4. Once Node.js is installed, you can run one of the following commands to install Cheerio in your terminal:
- npm install
- cheerio yarn add cheerio
Prerequirements:
- Node.js 5
- Axios: Make http requests from node.js. You can use Axios to send connection requests to the website you want to scrape. 6
Drawbacks:
- Does not include features such as screenshot capture or PDF generation.
- Does not support Javascript parsing.
- Incapable handling scraping dynamic pages.
Puppeteer evaluation
Puppeteer is a Node.js library designed for browser automation in particular. It is an open-source Node library, similar to Cheerio. Some of the main features of Puppeteer include:
- Puppeteer has an event-driven architecture. Event-driven architecture (EDA) is a software architecture that enables independent and interoperable operation of decoupled services. For example, if one service fails, the others will continue functioning. It allows for asynchronous communication between decoupled services.
- Puppeteer runs in headless mode. Developers and test automation engineers use headless mode to run tests. It reduces the time of testing. Headless mode is also beneficial for web scraping. Web scraping benefits from headless mode as well. Headless browsers collect data from web pages without rendering entire web pages. You are not required to wait for whole web pages to load visual elements.
- Puppeteer is a JavaScript Web Scraping Libraries for Node.js. Javascript rendering enables users to scrape dynamic web pages like single-page applications (SPAs).
Puppeteer installation: Puppeteer requires no setup; you can use it in your project by executing the command below.
Figure 3: Puppeteer installation script

When you install Puppeteer, a recent version of Chromium is automatically downloaded.
Drawbacks
- Puppeteer does not support video playback. Because Puppeteer is included with Chromium, it inherits all of Chromium’s media-related restrictions.
- Puppeteer is not compatible with HTTP Live Streaming (HLS). 8 Puppeteer controls a desktop version of Chromium/Chrome, so it does not support mobile-specific features.
Cheerio or Puppeteer: which is better for web scraping?
Cheerio does not render JavaScript documents. If you intend to scrape dynamic web pages such as Instagram, Twitter, and YouTube, you can use Puppeteer. It can be used to click buttons, submit forms etc. However, it is the best option if you intend to scrape static web pages. It makes it easier to parse HTML/XML documents and select elements from a given document.
Sponsored
If you intend to scrape well-protected websites such as Amazon, you need to integrate Cheerio and Puppeteer with a proxy solution to avoid being blocked. Bright Data offers various proxy server solutions for different web scraping use cases. To learn how to set up Puppeteer proxy settings and integrate with Bright Data’s Proxy servers, check out their guide on the topic.
Figure 4: A diagram of Bright Data’s proxy network

Further reading
Feel free to Download our whitepaper for a more in-depth understanding of web scraping:
Get Web Scraping Whitepaper
If you have more questions, do not hesitate contacting us:
Find the Right Vendors
- npm trends
- Cheerio
- MDN Web Docs
- Installing Node.js via package manager
- Node.js
- Axios
- Puppeteer
- Chrome Developers

Gülbahar is an industry analyst of AIMultiple. She received her bachelor’s degree in Business Administration from Dokuz Eylül University.

Source link
